
使用Docker容器
Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口,更重要的是容器性能开销极低。
总的来说,docker使得我们部署、发布、扩展、持续集成应用都更加的方便快速。作为开发者是肯定有必要学习下的。
容器(Containers)
为什么我们需要容器呢?先来看一看代码运行环境的历史,从中看出每次的优缺点。
历史
- 裸机
很久以前,你想要跑一个 Web 服务,你需要买或者去租一个文字服务器,我们称之为"裸机",您的代码实际上是在处理器上执行的。不过随之产生了一个问题,假如你的应用需要扩展,你需要去购买新的服务器,租新的机房去,需要大量人力去维护你的服务器。缺点是管理难。维护成本高。
- 虚拟机
虚拟机使你和机器之间增加了一层抽象,你可以在服务器上启动多个的 VM 实例,为 VM 分配固定的资源,这提供了很好的灵活性。而且虚拟机相对物理机,安全性也进一步提升。虚拟机是独立的操作系统,本身在裸机上运行,但是却无法窥视裸机上的文件和进程,而且一个 VM 实例崩溃了也并不影响其他实例。缺点是需要牺牲一定的性能作为代价。
- 公有云
可以从Microsoft Azure或Amazon Web Services之类的公有云供应商获取虚拟机。它会预先分配一定数量的内存和计算能力(虚拟核或vCore)。你不再需要支付昂贵的维护数据中心的费用,但你仍需要管理虚拟机上的软件。
- 容器
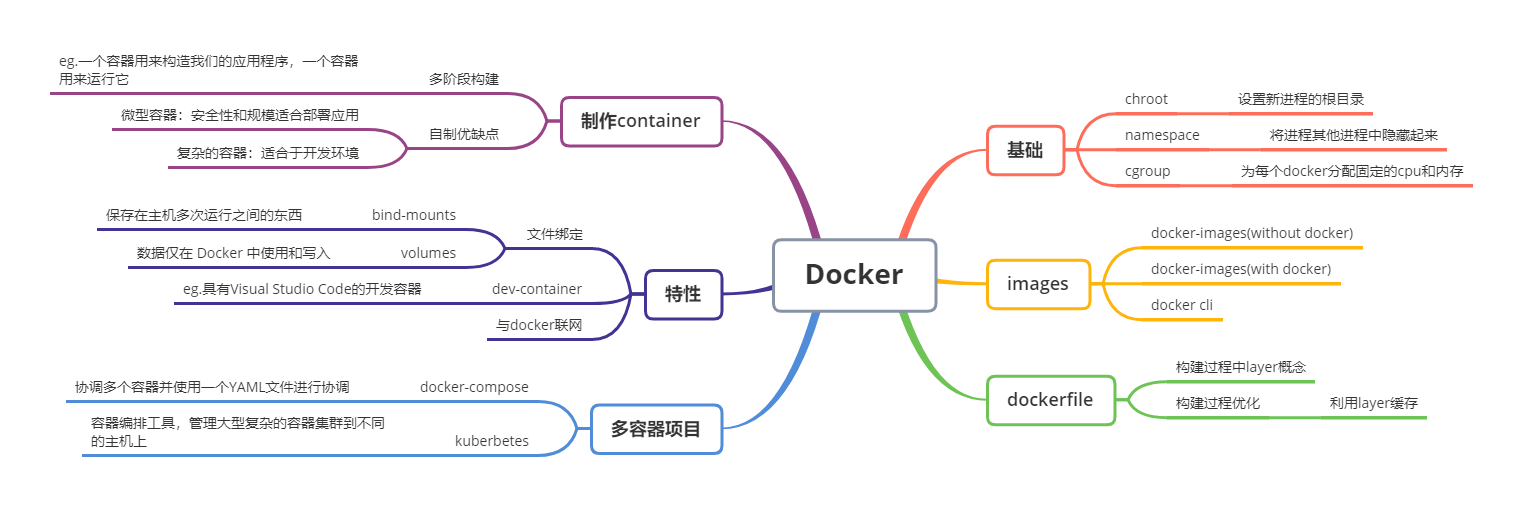
容器为我们提供了VM的许多安全性和资源管理功能,但又无需运行其他操作系统。它使用 chroot,namespace和cgroup将一组进程彼此分开。容器是部署代码的未来。
基本概念
chroot,namespace和cgroup作为容器的基本概念都有哪些作用呢?
chroot
chroot 作为 Linux 命令,允许我们设置新进程的根目录。在我们的容器用例中,我们设置容器的根目录,那么新的容器进程组看不到任何外部消息,消除了安全性问题,因为新进程在其根目录之外没有可见性。
namespace
namespace和cgroup均用于安全性和资源管理。chroot仅仅隔离了文件,Linux 其他用户还是可以看到计算机正在运行的所有进程,我们需要namespace来将你从其他进程中隐藏起来。namespace用来帮助容器之间保持隔离。
cgroups
试想一下每一个隔离的环境都可以访问服务器上的所有物理资源,一个用户因为内存泄漏将所用物理资源都用完,其他的用户该怎么办呢?
答案是利用cgroups为每个docker分配固定的cpu和内存等。
Docker
Docker是一种命令行工具,可大大简化创建,更新包装,分发和运行容器的过程。从本质上讲,这是一个命令行,用于以更便捷的方式实现我们对cgroups,namespace和chroot的操作。接下来让我们深入研究Docker的核心概念。
-
适用于Mac和Windows。Docker Desktop运行Docker 守护程序(守护程序仅表示始终在后台运行的程序),以便我们可以下载,运行和构建容器。
-
Docker Hub是预制容器的公共注册表。可以将其视为容器的npm。您可以从Docker Hub的基本容器开始,然后从那里开始,而不必自己手工完成所有事情。
不通过 Docker 使用images
预制的容器称为images。它们将容器的状态转储出去,打包并存储,以便以后使用。下例中让我们从Docker Hub中获取一个容器,获取并运行Ubuntu的最新Node.js容器。
1 | start docker contanier with docker running in it connected to host docker daemon |
Docker不仅可以为你做网络,挂载卷和其他事情,还为您做更多的工作,但足以说明Docker为您所做的工作的核心:创建一个新的环境,该环境由namespace隔离,并受cgroups限制,并且将您chroot它。通过上面的代码让我们知道Docker大致在帮着我们做什么工作。
通过 Docker 使用images
使用Docker进行操作要容易得多,
1 | docker run --interactive --tty alpine:3.10 # or, to be shorter: docker run -it alpine:3.10 |
这会使我们以root用户进入容器内部的Alpine ash shell。完成后,只需运行exit或按CTRL + D。
Docker 运行images有三种方式,
- 运行单个任务
1
docker container run alpine hostname
- 交互性运行任务
1
docker container run --interactive --tty --rm ubuntu bash
bash shell。--interactive 声明交互性,--tty 生成一个伪tty,--rm表明执行完之后删除。
- 在后台运行任务
1
2docker container run --detach --name mydb -e MYSQL_ROOT_PASS
docker exce -it mydb mysql --user=root --password=$MYSQL_ROOT_PASS --version
上面标明我们正在使用Node.js版本12,而Stretch是指Debian的版本(默认情况下,Node.js使用的版本)。
如果docker run -it node隐式运行该标签,则使用该latest标签。所以docker run -it node和docker run -it node:latest是一样的效果。如果需要 node 的 8.0 版本,可以运行 docker run -it node:8 bash
Docker-Cli 常见命令
| 名称 | 示例命令 | 作用 |
|---|---|---|
| pull | docker pull jturpin/hollywood |
允许您预提取容器以运行,会提前缓存到本地 |
| push | docker push xxxxx.com/abc-dev/image:1334 |
推送到您连接到的任何注册表 |
| inspect | docker inspect node |
检查容器的信息 |
| pause | docker pause <ID or name> |
暂停容器中的所有进程 |
| unpause | docker unpause <ID or name> |
取消暂停容器中的所有进程 |
| exec | docker exec <ID or name> ps aux |
使用ps aux查看计算机上正在运行的内容 |
| save | docker save logmanager:1.0 > logmanager.tar |
将image save成tar包 |
| load | docker load < my.tar |
将一个tar包load成一个image |
| history | docker history node |
查看此Docker映像的层组成如何随时间变化以及最近如何变化 |
| info | docker info |
查看有关主机系统的大量信息 |
| top | docker top <ID outputted by previous command> |
查看容器上运行的进程 |
| ps -all | docker ps --all |
显示除已运行的容器之外已停止运行的所有容器 |
| rm | docker rm <id or name> |
删除容器 |
| rmi | docker rmi mongo |
删除镜像 |
| logs | docker logs <id from previous command> |
查看正在容器日志 |
| restart | docker restart myrunoob |
重启容器 |
| search | docker search python |
查看 Docker Hub 是否存在容器 |
Dockerfile
Docker有一个名为的特殊文件Dockerfile,用来概述如何构建容器。Docker文件中的每一行都是有关如何更改Docker容器的新指令。Docker容器的一大关键在于它们应该是一次性的。您应该能够根据需求重复创建和删除容器。
Dockerfile示例
下面运行一个最简单的一个Docker容器,并且打印"hi lol"。
1 | FROM node:12-stretch |
每行(第一件事FROM,并CMD在这种情况下)被称为指令。从技术上讲,它们不必全部大写,但通常这样做是为了使文件更易于阅读。这些指令中的每条指令都将容器从之前的状态递增地更改,从而增加了layer(下面会介绍)。
如果你运行docker build .,每条指令之后,您将看到一个类似于我们一直在使用的容器ID的哈希。你知道那是为什么吗?这是因为这些层中的每一层本身都是有效的容器映像!使用docker build . --tag my-node-app会让运行容器更方便,docker run my-node-app。
Layer
对Node.js应用进行更改,并且重新运行构建过程的时候,Docker足够聪明,可以看到您的FROM,RUN和WORKDIR指令没有改变。再次构建的时候,它会使用之前缓存的镜像ID,只从你更改的文件开始重新构建。
1 | FROM node:12-stretch |
上面,先复制了package.json package-lock.json,并且安装了依赖,那么更改src文件的时候,可以避免完成的npm安装以来过程。这项措施对任何依赖项安装都是有用的,建议将其安装:apt-get,pip,cargo,gem等,以及任何长期运行的命令,例如从源代码构建一些命令。
制作微型容器
首先我们需要了解微型容器的优点和缺点。
微型容器的优点有:储存小,更容易迁移。更不容易送到错误的影响(如有python漏洞被利用等)。安全性和规模适合部署应用。
微型容器的缺点是:缺少了必要的工具包,不利于开发环境。
自制 Alpine Node.js 容器
新建Dockerfile:
1 | FROM alpine:3.10 |
多阶段构建
微型容器更适合项目的部署,但是开发中我们安装的一些依赖在部署的过程中并不需要。这里我们需要用到多阶段构建,一个容器用来构造我们的应用程序,一个容器用来运行它。C ++或Rust应用程序可能是一个很好的例子:它们需要大型工具链来编译应用程序,但是生成的二进制文件较小,并且不需要那些工具来实际运行它们。在JS中,或许我们生产中不需要TypeScript或Sass编译器,而仅需要编译文件。
1 | # build stage |
案例:静态资源展示
假如我们使用React,TypeScript和Sass构建一个非常基本的前端网站,使用Nginx来展示项目。我们需要使用多阶段的Dockerfile,使得文件在一个容器中构建该项目,使用Nginx在另一个容器中提供服务。
1 | FROM node:latest |
1 | docker build -t static-app . |
Docker的一些特性
bind-mounts
假如服务器运行一个Wordpress网站的服务,我们的内容放在容器中,那么容器就没法自由的销毁和重启了。这时,我们需要bind-mounts或者vloume。
上例中,使用Nginx的服务器,也能bind-mounts
1 | from the root directory of your CRA app |
解释一下上面的命令:
--mount,表示将从主机装入某些东西。type类型有两种bind和vloume。这里使用bind表示从主机挂在一些已存在的数据。source中,需要确定哪一部分对容器可读写。必须是一个绝对路径,这里使用"$(pwd)"来获取绝对路径。target表示我们希望将文件安装到容器中的位置。- 我们可以挂载更多的目录,并且可以将
bind和vloume混合使用。(我们可以使用另一个bind绑定配置,/etc/nginx/nginx.conf)
volumes
bind-mounts非常适合您需要在主机和容器之间共享数据时使用。容器多次运行,需要保存上一次的运算结果,使用volume会很有用。卷不仅可以在运行之间由相同的容器类型共享,而且可以在不同的容器之间共享。也许如果您有两个容器,并且想通过日志将日志合并到一个位置,则卷可以帮助实现这一点。
绑定挂载是由主机管理的文件系统。它们只是主机中装入容器的普通文件。卷是不同的,因为它们是Docker管理的新文件系统,由Docker管理并安装到您的容器中。这些由Docker管理的文件系统对主机系统不可见。(实际上可以找到)
下面展示一个例子,Node会读取某个文件,并添加文件的记录到文件。
1 | const dataPath = path.join(process.env.DATA_PATH || "./data.txt"); |
1 | docker build --tag=incrementor . |
我们使用该--env标志将DATA_PATH设置为希望Node.js写入文件的位置,并使用--mount它挂载一个名为的命名卷incrementor-data。您可以将其省略,它将是一个匿名卷,它将继续存在于容器之外,但在以后的运行中不会自动选择正确的卷。
何时使用 bind-mounts,何时使用 volume 呢?
需要保存在多次运行之间的东西,使用
bind-mounts数据仅在 Docker 中使用和写入,用
volumes。(使用Docker来备份,清理,提高安全性)
在开发环境中使用
通过定义Dockerfile,设置了项目所有的依赖关系,从而使它可以100%可重新创建。
举例:Hugo
我们的电脑上没有Go,却想使用Go上的Hugo新项目。Hugo是一个很棒的静态网站生成工具,用Go编写,使用hugo-builder可以快速开启一个项目,我们只需要绑定源文件。
1 | git clone https://github.com/btholt/hugo-example.git |
当然,Node.js对此也很有效,只不过,npm install会针对我们使用的OS专门构建依赖项。
具有Visual Studio Code的开发容器
我们需要在项目文件夹中创建一个名为.devcontainer的文件夹。其中放置两个文件,第一个是Dockerfile,我们将在其中设置开发环境。
1 | FROM node:12-stretch |
接下来创建一个devcontainer.json。
1 | { |
从这里关闭Visual Studio Code,然后再次重新打开该项目。您应该看到一个小提示,询问您是否要在容器中重新打开该项目。点击是!如果错过了该提示,请单击VSCode左下方的(通常为绿色)按钮,看起来有点像 >< 但推到一起。它应该可以选择在开发容器中打开该项目。
注意:如果您使用的是Windows,并且与WSL一起使用,则必须先将项目从 WSL中删除,然后才能在容器中重新打开该项目。希望这将是将来的顺畅体验。要从WSL进入Windows,请单击左下角的同一 >< 徽标,然后说在Windows中打开。从那里开始,以上说明应该起作用。
这里的几个关键事项:
- 我们可以有两个不同的Dockerfile用于开发和生产。我们可以有一个。我通常有两个,除非它们重叠太多,它们基本上是相同的。
- 我们通过确保每个人都为开发人员安装了正确的扩展程序来建立成功的同事。在这种情况下,我将Prettier和ESLint添加到了团队的环境中,以便他们在工作时可以得到即时反馈。
- 我们可以将设置添加到他们的环境中(例如保存时格式化),以便所有人的工作方式都一样。不用担心:如果不适合您的团队,您的团队可以覆盖其中的任何一个。
与Docker联网
介绍如何使用Docker进行手动联网,以便您了解Docker Compose和Kubernetes的功能。
如果我们的Node.js应用程序更加复杂,需要连接正在运行的MongoDB数据库,我们可以在同一容器启动数据库,这么做对于小项目来说行得通,如果我们直接使用mongo容器,则对于应用的拓展等更加友好。所以两个同时运行的容器如何通信和联网呢?
在Docker中进行网络连接的方法有多种,根据您所使用的操作系统,它们的工作方式有所不同。这是一个很深的主题,我们仅做简单介绍。默认的桥接网络一直在运行,可以查看:
1 | docker network ls |
桥接网络是一个一直存在的网络,如果需要,我们可以将其连接,但是Docker再次建议不要使用它,因此我们将创建自己的网络。还有一个主机网络,即主机计算机本身的网络。null如果要使用其他提供程序,或者要自己手动进行操作,则最后一个带有驱动程序的网络就是您要使用的网络。
继续运行 docker network create --driver=bridge app-net
完成此操作后,让我们启动MongoDB服务器。运行docker run -d --network=app-net -p 27017:27017 --name=db --rm mongo:3。
我们可以使用另一个 MongoDB容器(因为mongo除了拥有MongoDB服务器之外,它还具有客户端)。运行此:docker run -it --network=app-net --rm mongo:3 mongo --host db。这将是MongoDB容器通过我们的Docker网络连接到另一个容器的一个实例。
Node.js应用连接MongoDB
连接方法对任何数据库同样适用:MySQL,Postgres,Redis等。
添加读写MongoDB的工具
1 | const { MongoClient } = require("mongodb"); |
如果您的主机上运行了MongoDB,则可以绝对在本地运行此命令,因为默认的连接字符串将连接到本地MonogDB。但我们也将其保持打开状态,以便为应用程序提供环境变量,以便将其修改为其他容器。
因此,构建容器并使用以下命令运行它:
1 | npm install mongodb@3.3 # you need to add mongodb to your project |
多容器项目
我们一直在将您的应用程序部署到生产环境和创建开发环境的各个方面混合在一起。有时我们需要协调多个容器,下面介绍一些协调的方法。
Docker-componse
Docker Compose使我们能够协调多个容器并使用一个YAML文件进行协调。如果您正在开发Node.js应用程序并且需要数据库,缓存,或者即使您在两个或以上相互依赖或以上所有的容器中有两个以上的独立应用程序,这也很棒!Docker Compose使定义这些容器之间的关系并使它们全部运行在一起变得非常简单docker-compose up。
如果你需要部署Docker容器,Docker Compose适用于生产环境,如果你是开发人员,希望GitHub Actions或某些CI / CD提供程序启动多个环境以快速运行某些测试时,Docker Compose在CI / CD场景中也非常有用。
让我们开始使用之前的应用程序:一个通过Node.js应用程序连接到MongoDB数据库的应用程序。根目录创建docker-componse.yml
1 | version: "3" |
首先version表示当前使用的Docker componse YAML版本。
在service定义此特定应用程序所需的容器时。我们有两个:web容器(这是我们的应用程序)和db容器,即MongoDB。然后,我们确定Dockerfile所在的位置build,要公开的端口ports,要创建的卷volumes(此处正在装入代码,以便我们可以保留代码而不必重建映像),以及environment使用该字段的变量。
links字段,表示web容器需要连接到db容器。这意味着Docker将首先启动此容器,然后将其联网到该web容器。
运行docker-compose up就能立即开始我们的项目,我们在web项目下编写我们的Dockerfile,可以使得开发效率更高。
1 | FROM node:latest |
没使用Kubernetes之前,我们可以使用docker-compose up --scale web=10将Web容器扩展到10个同时运行的容器。但是目前行不通,因为他们都试图在3000端口侦听主机。但是我们可以使用NGINX或HAProxy之类的方法在容器之间进行负载平衡。这是一个更高级的用例,对Compose则用处不大,因为那时候您可能应该只使用Kubernetes或类似的东西。
Kubernetes
Kubernetes又可以简称k8s(k然后8个字母然后s)。它是作为容器编排工具,管理大型复杂的容器集群到不同的主机上。
关于k8s的一些基本概念:
- master服务器,作为协调一切的服务器,是集群的大脑。
- nodes服务器,用来实际运行服务的服务器。
- 技术上讲,一个节点只是部署目标,可以是VM或者Docker。
- 本质上讲,Pod是集群的原子,表示多个容器需要相互依赖启动,例如MongoDB pod和app pod分开,可以单独拓展。
- 一个service是一组pods组成的一个backend(可以是服务,也可以是其他东西如机器学习,数据库,缓存)。一个微服务的提供,背后应该是一组微服务。pod按比例放大或者缩小,不依靠一个ip来作为服务,应该使用service作为可靠的切入点。服务之间可以互相通信。
- deployment用来描述你所需的pod状态,以及让kubernetes使集群进入状态。
我们需要新的cli工具:kubectl。kubectl(有关如何安装的信息,请参见此处)是允许您控制任何 Kubernetes集群的工具,无论它是本地的还是在云中。它是用于管理Kubernetes的单个统一CLI。
之后,需要在minikube使用Docker桌面内置的Kubernetes支持之间进行选择。如果都一样,我建议使用Docker Desktop,因为它更易于使用。
Docker Desktop附带了非常简单的Kubernetes支持。很高兴学习,但是有一些限制。如果您需要做更复杂的事情,请使用minikube。要在Docker Desktop上启用Kubernetes,请打开Docker Desktop的首选项,导航到Kubernetes选项卡,启用它,在询问是否可以重新启动时接受它,然后等待几分钟。
minikube(有关安装方法,请参见此处)是一个开发工具,可让您的Kubernetes集群在本地计算机上运行。您将只能在本地使用此功能。
引用
- 本文标题:使用Docker容器
- 本文作者:hddhyq
- 本文链接:https://hddhyq.github.io/2020/05/18/intro-docker/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!