
你不知道的JS总结-作用域和闭包(一)
这几天读了下《你不知道的JavaScript(上卷)》,对于书中作用域和闭包的知识点做一下总结 # 第 1 章 作用域是什么 要了解作用域的规则,首先需要了解简单的编译原理。 ## 编译原理 尽管通常将 JavaScript 归类为“动态”或“解释执行”语言,但事实上它是一门编译语言。
在传统编译语言的流程中,程序中的一段源代码在执行之前会经历三个步骤,统称为“编译”。 * 分词/词法分析(Tokenizing/Lexing)
这个过程会将由字符组成的字符串分解成(对编程语言来说)有意义的代码块,这些代码块被称为词法单元(token)。 如:var a = 2; => var、a、=、2 、; * 解析/语法分析(Parsing)
这个过程是将词法单元流(数组)转换成一个由元素逐级嵌套所组成的代表了程序语法结构的树。这个树被称为“抽象语法树”(Abstract Syntax Tree,AST)。
代码生成
将 AST 转换为可执行代码的过程称被称为代码生成。
理解作用域
需要理解三个处理过程中的参与者: * 引擎
从头到尾负责整个 JavaScript 程序的编译及执行过程。 * 编译器
引擎的好朋友之一,负责语法分析及代码生成等脏活累活(详见前一节的内容)。 * 作用域
引擎的另一位好朋友,负责收集并维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。
例子: var a = 2;
变量的赋值操作会执行两个动作,首先编译器会在当前作用域中声明一个变量(如果之前没有声明过),然后在运行时引擎会在作用域中查找该变量,如果能够找到就会对它赋值。
在赋值中,对于引擎来讲,引擎会为变量 a 进行 LHS 查询。另外一个查找的类型叫作 RHS。
RHS 查询与简单地查找某个变量的值别无二致,而 LHS 查询则是试图找到变量的容器本身,从而可以对其赋值。RHS 并不是真正意义上的“赋值操作的右侧”,更准确地说是“非左侧”。
你可以将 RHS 理解成 retrieve his source value(取到它的源值)。
作用域嵌套
当一个块或函数嵌套在另一个块或函数中时,就发生了作用域的嵌套。因此,在当前作用域中无法找到某个变量时引擎就会在外层嵌套的作用域中继续查找,直到找到该变量,或抵达最外层的作用域(也就是全局作用域)为止。
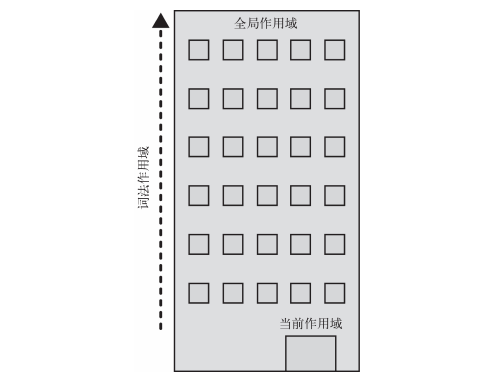
不管是LHS 和 RHS都需要对作用域按照上图进行查找。一旦抵达全局作用域,无论你有没有找到所需变量,查找过程都会终止。
异常
LHS和RHS,在最终没有找到变量的时候处理方式会有差异: * RHS 抛出异常ReferenceError * LHS 在严格模式,抛出异常ReferenceError,正常模式,会创建一个具有该名称的变量,并将其返还给引擎。
RHS 中,如果找到一个变量对这个变量进行不合理的操作。会抛出TypeError
ReferenceError 同作用域判别失败相关,而 TypeError 则代表作用域判别成功了。
小结
作用域是一套规则,用于确定在何处以及如何查找变量(标识符)。如果查找的目的是对变量进行赋值,那么就会使用 LHS 查询;如果目的是获取变量的值,就会使用 RHS 查询。赋值操作符会导致 LHS 查询。=操作符或调用函数时传入参数的操作都会导致关联作用域的赋值操作。
JavaScript 引擎首先会在代码执行前对其进行编译,在这个过程中,像 var a = 2 这样的声明会被分解成两个独立的步骤: 1. 首先,var a 在其作用域中声明新变量。这会在最开始的阶段,也就是代码执行前进行。 2. 接下来,a = 2 会查询(LHS 查询)变量 a 并对其进行赋值。
LHS 和 RHS 查询都会在当前执行作用域中开始,如果有需要(也就是说它们没有找到所需的标识符),就会向上级作用域继续查找目标标识符,这样每次上升一级作用域(一层楼),最后抵达全局作用域(顶层),无论找到或没找到都将停止。不成功的 RHS 引用会导致抛出 ReferenceError 异常。不成功的 LHS 引用会导致自动隐式地创建一个全局变量(非严格模式下),该变量使用 LHS 引用的目标作为标识符,或者抛出 ReferenceError 异常(严格模式下)。
第 2 章 词法作用域
作用域共有两种主要的工作模型。第一种是最为普遍的,被大多数编程语言所采用的 词法作用域 ,我们会对这种作用域进行深入讨论。另外一种叫作 动态作用域,仍有一些编程语言在使用(比如 Bash 脚本、Perl 中的一些模式等)。
词法阶段
第 1 章介绍过,大部分标准语言编译器的第一个工作阶段叫作词法化(也叫单词化)。回忆一下,词法化的过程会对源代码中的字符进行检查,如果是有状态的解析过程,还会赋予单词语义。
简单地说,词法作用域就是定义在词法阶段的作用域。换句话说,词法作用域是由你在写代码时将变量和块作用域写在哪里来决定的,因此当词法分析器处理代码时会保持作用域不变(大部分情况下是这样的)。
1 | function foo(a) { |
这个例子中有三个逐级嵌套的作用域。为了帮助理解,可以将它们想象成几个逐级包含 的气泡。 
- 包含着整个全局作用域,其中只有一个标识符:foo。
- 包含着 foo 所创建的作用域,其中有三个标识符:a、bar 和 b。
- 包含着 bar 所创建的作用域,其中只有一个标识符:c
没有任何函数的气泡可以(部分地)同时出现在两个外部作用域的气泡中,就如同没有任何函数可以部分地同时出现在两个父级函数中一样。
作用域查找会在找到第一个匹配的标识符时停止。在多层的嵌套作用域中可以定义同名的标识符,这叫作“ 遮蔽效应 ”(内部的标识符“遮蔽”了外部的标识符)。抛开遮蔽效应,作用域查找始终从运行时所处的最内部作用域开始,逐级向外或者说向上进行,直到遇见第一个匹配的标识符为止。
无论函数在哪里被调用,也无论它如何被调用,它的词法作用域都只由函数被声明时所处的位置决定。
欺骗词法
如果词法作用域完全由写代码期间函数所声明的位置来定义,怎样才能在运行时来“修改”(也可以说欺骗)词法作用域呢?
JavaScript 中有两种机制来实现这个目的 1. eval
JavaScript 中的 eval(..) 函数可以接受一个字符串为参数,并将其中的内容视为好像在书写时就存在于程序中这个位置的代码。 2. with JavaScript 中另一个难以掌握(并且现在也不推荐使用)的用来欺骗词法作用域的功能是with 关键字。
性能
这是我们抛弃上述两个方法的主要原因,
JavaScript 引擎会在编译阶段进行数项的性能优化。其中有些优化依赖于能够根据代码的词法进行静态分析,并预先确定所有变量和函数的定义位置,才能在执行过程中快速找到标识符。
但如果引擎在代码中发现了 eval(..) 或 with,它只能简单地假设关于标识符位置的判断都是无效的,因为无法在词法分析阶段明确知道 eval(..) 会接收到什么代码,这些代码会如何对作用域进行修改,也无法知道传递给 with 用来创建新词法作用域的对象的内容到底是什么。
如果代码中大量使用 eval(..) 或 with,那么运行起来一定会变得非常慢。无论引擎多聪明,试图将这些悲观情况的副作用限制在最小范围内,也无法避免如果没有这些优化,代码会运行得更慢这个事实。
小结
词法作用域意味着作用域是由书写代码时函数声明的位置来决定的。编译的词法分析阶段基本能够知道全部标识符在哪里以及是如何声明的,从而能够预测在执行过程中如何对它们进行查找。
JavaScript 中有两个机制可以“欺骗”词法作用域:eval(..) 和 with。前者可以对一段包含一个或多个声明的“代码”字符串进行演算,并借此来修改已经存在的词法作用域(在运行时)。后者本质上是通过将一个对象的引用当作作用域来处理,将对象的属性当作作用域中的标识符来处理,从而创建了一个新的词法作用域(同样是在运行时)。
这两个机制的副作用是引擎无法在编译时对作用域查找进行优化,因为引擎只能谨慎地认为这样的优化是无效的。使用这其中任何一个机制都将导致代码运行变慢。不要使用它们。 # 第 3 章 函数作用域和块作用域 ## 函数中的作用域 1
2
3
4
5
6
7
8
9function foo(a) {
var b = 2;
// 一些代码
function bar() {
// ...
}
// 更多的代码
var c = 3;
}
函数作用域的含义是指,属于这个函数的全部变量都可以在整个函数的范围内使用及复用(事实上在嵌套的作用域中也可以使用)。这种设计方案是非常有用的,能充分利用JavaScript 变量可以根据需要改变值类型的“动态”特性。
隐藏内部实现
对函数的传统认知就是先声明一个函数,然后再向里面添加代码。但反过来想也可以带来一些启示:从所写的代码中挑选出一个任意的片段,然后用函数声明对它进行包装,实际上就是把这些代码“隐藏”起来了。
有很多原因促成了这种基于作用域的隐藏方法。它们大都是从最小特权原则中引申出来的,也叫最小授权或最小暴露原则。这个原则是指在软件设计中,应该最小限度地暴露必要内容,而将其他内容都“隐藏”起来,比如某个模块或对象的 API 设计。
1 | function doSomething(a) { |
上述的例子中,就是一个反例,将应该私有的变量b和函数doSomethingElse(..)暴露给了外部作用域。
1 | function doSomething(a) { |
修改后的代码,b和 doSomethingElse(..)都无法从外部被访问。
规避冲突 1
2
3
4
5
6
7
8
9
10function foo() {
function bar(a) {
i = 3; // 修改 for 循环所属作用域中的 i
console.log( a + i );
}
for (var i=0; i<10; i++) {
bar( i * 2 ); // 糟糕,无限循环了!
}
}
foo();
这里我们能选用两种方法,一种新声明一个本地变量,var i = 3;。另一种,新添加一个标识符名称,比如 var j = 3。
软件设计在某种情况下可能自然而然地要求使用同样的标识符名称,所以通过作用域来“隐藏”内部声明是唯一的最佳选择。
- 全局命名空间 变量冲突的一个典型例子存在于全局作用域中。当程序中加载了多个第三方库时,如果它们没有妥善地将内部私有的函数或变量隐藏起来,就会很容易引发冲突。
这些库通常会在全局作用域中声明一个名字足够独特的变量,通常是一个对象。这个对象被用作库的命名空间,所有需要暴露给外界的功能都会成为这个对象(命名空间)的属性,而不是将自己的标识符暴漏在顶级的词法作用域中。 1
2
3
4
5
6
7
8
9var MyReallyCoolLibrary = {
awesome: "stuff",
doSomething: function() {
// ...
},
doAnotherThing: function() {
// ...
}
};
- 模块管理 这种避免冲突的方法和现代的木块机制很接近,从众多的模块管理器挑选一个使用。使用这些工具,任何库都无需将标识符加入到全局作用域中,而是通过依赖管理器的机制将库的标识符显式地导入到另外一个特定的作用域中。
显而易见,这些工具并没有能够违反词法作用域规则的“神奇”功能。它们只是利用作用域的规则强制所有标识符都不能注入到共享作用域中,而是保持在私有、无冲突的作用域中,这样可以有效规避掉所有的意外冲突。
函数作用域
在前面我们知道了,在任意代码片段外部添加包装函数,可以讲变量和函数定义“隐藏”起来,外部作用域无法访问包装函数内部的任何内容。
这个方法也有不理想之处。我们必须声明一个具名函数,这也就意味着,这个具名函数的名称已经“污染”了所在作用域。其次,必须显示的调用这个具名函数,才能运行其中的代码。
如果函数不需要函数名(或者至少函数名可以不污染所在作用域),并且能够自动运行,这将会更加理想。
JS中的同时解决两种问题的方案: 1
2
3
4
5
6
7var a = 2;
(function foo(){ // <-- 添加这一行
var a = 3;
console.log( a ); // 3
})(); // <-- 以及这一行
console.log( a ); // 2
包装函数的声明以 (function... 而不仅是以 function... 开始。尽管看上去这并不是一个很显眼的细节,但实际上却是非常重要的区别。函数会被当作函数表达式而不是一个标准的函数声明来处理。其实就是立即执行了。
区分函数声明和表达式最简单的方法是看 function 关键字出现在声明中的位 置(不仅仅是一行代码,而是整个声明中的位置)。如果 function 是声明中 的第一个词,那么就是一个函数声明,否则就是一个函数表达式。
函数声明 和 函数表达式 之间最重要的区别是它们的名称标识符将会绑定在何处。
(function foo(){ .. }) 作为函数表达式意味着 foo 只能在 .. 所代表的位置中被访问,外部作用域则不行。foo 变量名被隐藏在自身中意味着不会非必要地污染外部作用域。
匿名和具名
1 | setTimeout( function() { |
上述的定时的代码片段,我们很熟悉,这就是 匿名函数表达式 , 因为function().. 没有名称标识符。
匿名函数书写起来简单便捷,不过有几个缺点需要考虑。 1. 匿名函数在栈追踪中不会显示出有意义的函数名,使得调试很困难。 2. 如果没有函数名,当函数需要引用自身时只能使用已经过期的 arguments.callee 引用,比如在递归中。另一个函数需要引用自身的例子,是在事件触发后事件监听器需要解绑自身。 3. 匿名函数省略了对于代码可读性 / 可理解性很重要的函数名。一个描述性的名称可以让代码不言自明。
立即执行函数表达式
IIFE, 代表立即执行函数表达式(Immediately Invoked Function Expression);
函数名对于IIFE不是必需的,IIFE 最常见的用法是使用一个匿名函数表达式。 * IIFE 的一个非常普遍的进阶用法是把它们当作函数调用并传递参数进去。 * IIFE 另一个场景,解决undefined 标识符的默认值被错误覆盖导致的异常(虽然不常见)。 * IIFE 是倒置代码的运行顺序,将需要运行的函数放在第二位,在 IIFE执行之后当作参数传递进去。
块作用域
1 | for (var i=0; i<10; i++) { |
我们在 for 循环的头部直接定义了变量 i,通常是因为只想在 for 循环内部的上下文中使用 i,而忽略了 i 会被绑定在外部作用域(函数或全局)中的事实。
1 | var foo = true; |
使用 var 声明变量时,它写在哪里都是一样的,因为它们最终都会属于外部作用域。这段代码是为了风格更易读而伪装出的形式上的块作用域,如果使用这种形式,要确保没在作用域其他地方意外地使用 bar 只能依靠自觉性。
块作用域是一个用来对之前的最小授权原则进行扩展的工具,将代码从在函数中隐藏信息扩展为在块中隐藏信息。实现方法: 1. with 2. try/catch catch分句会创建一个块作用域,其中声明的变量仅在 catch 内部有效。 3. let
let
这里我们着重介绍下,let的实现原理。
let关键字可以将变量绑定到所在的任意作用域中,通常是{ .. } 内部.换句话说,let为其声明的变量隐式地了所在的块作用域。 1
2
3
4
5
6
7var foo = true;
if (foo) {
let bar = foo * 2;
bar = something( bar );
console.log( bar );
}
console.log( bar ); // ReferenceError
在开发和修改代码的过程中,如果没有密切关注哪些块作用域中有绑定的变量,并且习惯性地移动这些块或者将其包含在其他的块中,就会导致代码变得混乱。
显示的块作用域,可以解决上述问题。 1
2
3
4
5
6
7
8
9var foo = true;
if (foo) {
{ // <-- 显式的快
let bar = foo * 2;
bar = something( bar );
console.log( bar );
}
}
console.log( bar ); // ReferenceError
- 垃圾收集
另一个块作用域非常有用的原因和闭包及回收内存垃圾的回收机制相关。通过块作用域,能够让引擎知道我们执行后的代码片段不需要继续保存。
- let循环
1 | for (let i=0; i<10; i++) { |
for 循环头部的 let 不仅将 i 绑定到了 for 循环的块中,事实上它将其重新绑定到了循环的每一个迭代中,确保使用上一个循环迭代结束时的值重新进行赋值。
下面通过另一种方式来说明每次迭代时进行重新绑定的行为:
1 | { |
const
同样可以用来创建块作用域变量,但其值是固定的(常量)。
小结
函数是 JavaScript 中最常见的作用域单元。本质上,声明在一个函数内部的变量或函数会在所处的作用域中“隐藏”起来,这是有意为之的良好软件的设计原则。
但函数不是唯一的作用域单元。块作用域指的是变量和函数不仅可以属于所处的作用域,也可以属于某个代码块(通常指 { .. } 内部)。
从 ES3 开始,try/catch 结构在 catch 分句中具有块作用域。
在 ES6 中引入了 let 关键字(var 关键字的表亲),用来在任意代码块中声明变量。if(..) { let a = 2; } 会声明一个劫持了 if 的 { .. } 块的变量,并且将变量添加到这个块中。
有些人认为块作用域不应该完全作为函数作用域的替代方案。两种功能应该同时存在,开发者可以并且也应该根据需要选择使用何种作用域,创造可读、可维护的优良代码。
- 本文标题:你不知道的JS总结-作用域和闭包(一)
- 本文作者:hddhyq
- 本文链接:https://hddhyq.github.io/2018/02/05/你不知道的JS总结-作用域和闭包(一)/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!